多服务器部署架构 数据处理与存储服务的分布式实践
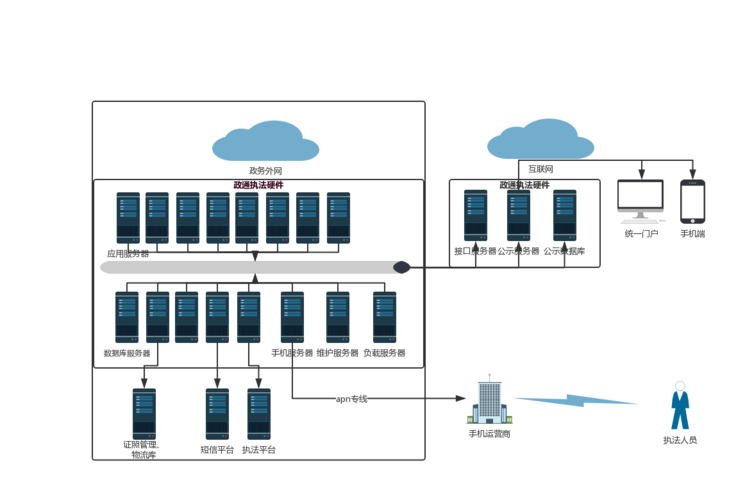
在当今数字化时代,数据处理与存储服务的规模和复杂性日益增长,单一服务器已难以满足高并发、高可用性和大数据处理的需求。多服务器部署,通常被称为分布式系统或集群架构,已成为企业级数据处理与存储服务的标准解决方案。
多服务器部署的核心概念
多服务器部署指的是将应用程序、数据处理任务和存储资源分散到多台服务器上,通过协同工作来提供服务。这种架构模式主要包括以下几种形式:
- 负载均衡集群:通过分发请求到多台服务器,避免单点过载,提高系统吞吐量和响应速度。
- 高可用集群:通过冗余设计确保服务在部分服务器故障时仍能正常运行。
- 分布式计算集群:将大规模计算任务拆解到多台服务器并行处理,典型代表如Hadoop、Spark。
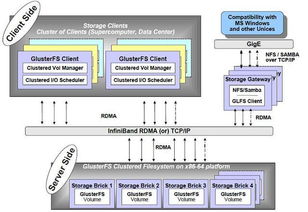
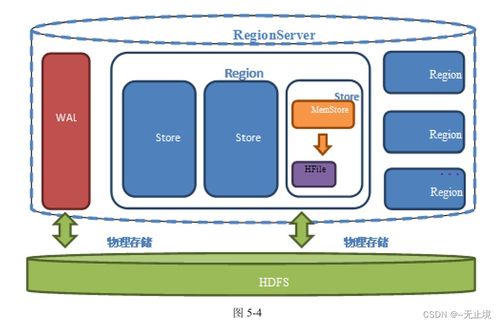
- 分布式存储系统:数据分散存储在多个节点,如HDFS、Ceph、云存储服务等。
数据处理服务的多服务器部署
对于数据处理服务,多服务器部署能显著提升处理能力和效率:
- 并行处理框架:如Apache Flink、Kafka Streams支持在集群中并行处理数据流。
- 微服务架构:将数据处理功能拆分为独立服务部署在不同服务器,提高模块化和可维护性。
- 容器化部署:使用Docker、Kubernetes等技术实现数据处理服务的弹性伸缩和快速部署。
数据存储服务的多服务器部署
数据存储服务的多服务器部署关注数据一致性、可靠性和访问性能:
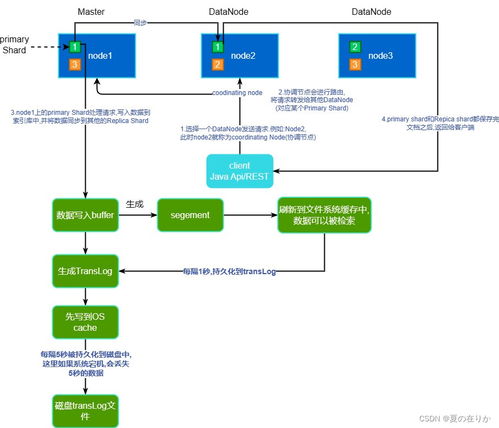
- 分布式数据库:如Cassandra、MongoDB分片集群,将数据分布到多个节点。
- 对象存储集群:如MinIO、Swift,提供可扩展的存储空间。
- 复制与分片技术:通过数据复制保证高可用,通过分片实现水平扩展。
关键技术与挑战
实施多服务器部署需解决以下关键技术问题:
- 一致性协议:如Raft、Paxos算法确保分布式系统中的数据一致性。
- 服务发现与注册:如Consul、Etcd帮助服务器动态发现和通信。
- 监控与运维:集中日志收集、性能监控和自动化运维工具链。
- 安全与隔离:网络隔离、访问控制和数据加密保障分布式环境安全。
实际应用场景
- 互联网平台:电商、社交媒体的用户数据和交易处理。
- 物联网系统:海量设备数据的实时采集与分析。
- 金融科技:高频交易、风险计算的大规模数据处理。
- 科学研究:基因组学、气候模拟等领域的计算密集型任务。
未来发展趋势
随着边缘计算和混合云架构的兴起,多服务器部署正向着更异构、更智能的方向发展:
- 云边端协同:中心云、边缘节点和终端设备的协同处理。
- Serverless架构:进一步抽象服务器管理,实现更细粒度的资源调度。
- AI驱动的运维:利用机器学习优化资源分配和故障预测。
多服务器部署作为数据处理和存储服务的核心架构模式,通过分布式技术和集群管理,实现了性能、可靠性和可扩展性的显著提升。企业需要根据自身业务特点选择合适的部署策略,并持续优化以适应不断变化的技术 landscape。
如若转载,请注明出处:http://www.ghostplans.com/product/33.html
更新时间:2026-06-18 20:29:58