云上Hadoop之最佳实践 优化数据处理与存储服务
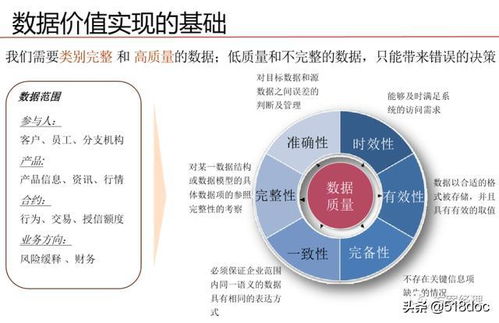
随着大数据技术的快速发展,云上Hadoop已成为企业处理海量数据的首选方案。它不仅提供了弹性的计算和存储资源,还通过云服务的灵活性和可扩展性,大幅降低了大数据平台的运维成本。本文将探讨云上Hadoop的最佳实践,涵盖数据处理和存储服务的关键优化策略,帮助企业高效利用云计算资源,提升数据处理效率。
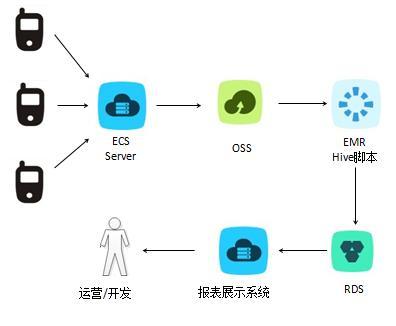
在数据处理方面,云上Hadoop的最佳实践包括合理配置集群资源、采用分布式计算框架(如MapReduce或Spark)以及优化数据分区与压缩。通过动态调整集群节点数量,企业可以根据业务负载实现成本效益最大化。实施增量数据处理和流式计算,能够实时响应业务需求,避免数据积压问题。利用云服务提供的数据湖架构,可以统一管理结构化和非结构化数据,简化ETL流程,加速数据洞察。
在存储服务方面,云上Hadoop推荐采用对象存储(如AWS S3或阿里云OSS)作为数据持久层,以实现高可用和低成本存储。通过设置生命周期策略,自动将冷数据迁移至归档存储,能够进一步优化成本。数据备份与容灾也是关键环节,建议采用多区域复制和快照技术,确保数据安全性和业务连续性。结合数据加密和访问控制机制,可以加强数据隐私保护,符合合规要求。
云上Hadoop的最佳实践不仅依赖于技术配置,还需结合业务场景进行持续优化。通过合理的数据处理和存储策略,企业能够构建高效、可靠的大数据平台,为数字化转型提供坚实支撑。随着云计算技术的不断演进,未来云上Hadoop将在AI集成和边缘计算领域发挥更大潜力,值得持续关注和探索。
如若转载,请注明出处:http://www.ghostplans.com/product/21.html
更新时间:2026-06-18 08:15:20